Introduction¶
What is an event?¶
The term ‘event’ is used in discussions about event sourcing more or less as an abbreviation which refers to a very particular kind of event: an individual, atomic, immutable decision originated by the domain model of a software application.
The commonsensical notion “event” has a broader meaning. Firstly, it includes all the other atomic “actual occasions” of experience that result in all the other stubborn facts which together make up the past. Such things importantly do not change. They are what they are. But the commonsensical meaning also includes inter-related sets of such things: “societies” of actual occasions, enduring objects that experience adventures of change. For example, the ordinary physical and social objects that we encounter in daily life that are each built up from an on-going history of inter-related decisions. In this sense, a software system is also an event. A developer is also an event. And so is her cat.
As Gilles Deleuze wrote in his book on Leibniz when discussing Alfred North Whitehead’s modern process philosophy:
“A concert is being performed tonight. It is the event. Vibrations of sound disperse, periodic movements go through space with their harmonics or submultiples. The sounds have inner qualities of height, intensity, and timbre. The sources of the sounds, instrumental or vocal are not content only to send the sounds out: each one perceives its own, and perceives the others whilst perceiving its own. These are active perceptions that are expressed among each other, or else prehensions that are prehending one another: ‘First the solitary piano grieved, like a bird abandoned by its mate; the violin heard its wail and responded to it like a neighbouring tree. It was like the beginning of the world….’”
However, the events of an event-sourced application are a very specific kind of event. They are the individual decisions originated by a domain model. They end up as immutable database records built up as an append-only log. And it is this log of events that is used as the “source of truth” to determine the current state of an application.
What is event sourcing?¶
One definition of event sourcing suggests the state of an event-sourced application is determined by a sequence of events. Another definition has event sourcing as a persistence mechanism for domain-driven design.
Whilst the basic event sourcing patterns are quite simple and can be reproduced in code for each project, event sourcing as a persistence mechanism for domain-driven design appears as a “conceptually cohesive mechanism” and so can be partitioned into a “separate lightweight framework”.
Quoting from Eric Evans’ book Domain-Driven Design:
“Partition a conceptually COHESIVE MECHANISM into a separate lightweight framework. Particularly watch for formalisms for well-documented categories of algorithms. Expose the capabilities of the framework with an INTENTION-REVEALING INTERFACE. Now the other elements of the domain can focus on expressing the problem (‘what’), delegating the intricacies of the solution (‘how’) to the framework.”
And that’s why this library was created.
This library¶
This is a library for event sourcing in Python. At its core, this library supports storing and retrieving sequences of events, such as the domain events of event-sourced aggregates in a domain-driven design, and snapshots of those aggregates. A variety of schemas and technologies can be used for storing events, and this library supports several of these possibilities.
To demonstrate how storing and retrieving domain events can be used effectively as a persistence mechanism in an event-sourced application, this library includes base classes and examples of event-sourced aggregates and event-sourced applications.
It is possible using this library to define an entire event-driven system of event-sourced applications independently of infrastructure and mode of running. That means system behaviours can be rapidly developed whilst running the entire system synchronously in a single thread with a single in-memory database. And then the system can be run asynchronously on a cluster with durable databases, with the system effecting exactly the same behaviour.
Design overview¶
The design of the library follows the notion of a “layered” or “onion” or “hexagonal” architecture in that there are separate modules for application, domain, persistence, and interface. The interface module depends on the application module. The application module depends on the domain module and the persistence module. The persistence module depends on the domain module. The domain module does not depend on any of the other modules. All these modules depend only on the Python Standard Library.
Buy the book¶
Buy the book Event Sourcing in Python for a detailed discussion of the design patterns which structure the library code.

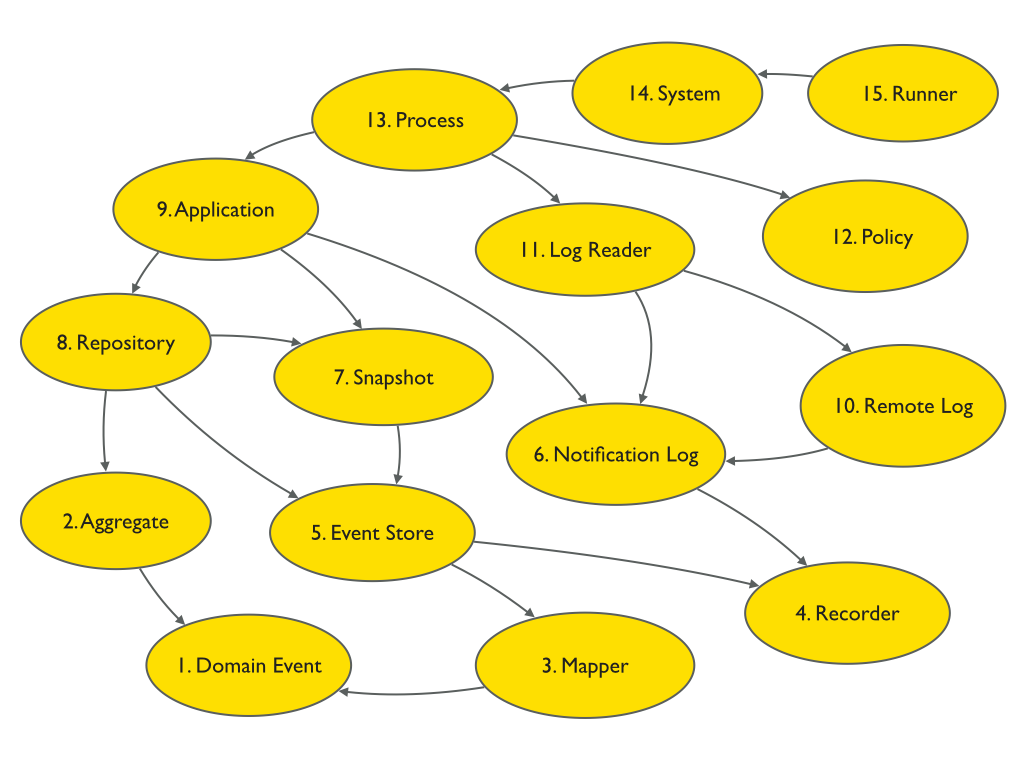
The book has three parts, with five chapters in each part.
Part 1 is about domain models. It has patterns to define, trigger, and store domain model events, and to project domain model events into the enduring objects which trigger them.
Domain Event
Aggregate
Mapper
Recorder
Event Store
Part 2 is about applications. It has patterns to unify the components of an event-sourced application, and to propagate the state of the application.
Notification Log
Snapshot
Repository
Application
Remote Log
Part 3 is about systems, and has patterns to process events and to define and run systems of applications that process domain model events.
Log Reader
Policy
Process
System
Runner
Each chapter describes one pattern, one characteristic occasion of design, one building block for event-sourced Domain-Driven Design. The descriptions are each intended to contribute determination to future design events that have the particular character of that pattern. Each chapter includes working examples that illustrate the characterised occasion of design, but which could be varied by the reader in different ways. The chapter examples build on examples from previous chapters.
Synopsis¶
Use the library’s Application class to define an event-sourced application.
Add command and query methods that use event-sourced aggregates.
from eventsourcing.application import Application
class DogSchool(Application):
def register_dog(self, name):
dog = Dog(name)
self.save(dog)
return dog.id
def add_trick(self, dog_id, trick):
dog = self.repository.get(dog_id)
dog.add_trick(trick)
self.save(dog)
def get_dog(self, dog_id):
dog = self.repository.get(dog_id)
return {'name': dog.name, 'tricks': tuple(dog.tricks)}
Use the library’s Aggregate class and the @event decorator to define
event-sourced aggregates. Aggregate events will be triggered
when decorated methods are called, and the decorated method bodies will be
used to mutate the state of the aggregate.
from eventsourcing.domain import Aggregate, event
class Dog(Aggregate):
@event('Registered')
def __init__(self, name):
self.name = name
self.tricks = []
@event('TrickAdded')
def add_trick(self, trick):
self.tricks.append(trick)
Optionally configure an application by setting environment variables, for example to enable aggregate caching or to specify a persistence module.
import os
# Enable aggregate caching.
os.environ['AGGREGATE_CACHE_MAXSIZE'] = '1000'
# Use SQLite.
os.environ['PERSISTENCE_MODULE'] = 'eventsourcing.sqlite'
os.environ['SQLITE_DBNAME'] = ':memory:'
Construct an application object by calling the application class.
application = DogSchool()
Evolve the state of the application by calling command methods.
dog_id = application.register_dog('Fido')
application.add_trick(dog_id, 'roll over')
application.add_trick(dog_id, 'fetch ball')
Access the state of the application by calling query methods.
dog_details = application.get_dog(dog_id)
assert dog_details['name'] == 'Fido'
assert dog_details['tricks'] == ('roll over', 'fetch ball')
Select event notifications from the notification log.
notifications = application.notification_log.select(start=1, limit=10)
assert len(notifications) == 3
assert notifications[0].id == 1
assert notifications[1].id == 2
assert notifications[2].id == 3
Features¶
Flexible event store — flexible persistence of domain events. Combines an event mapper and an event recorder in ways that can be easily extended. Mapper uses a transcoder that can be easily extended to support custom model object types. Recorders supporting different databases can be easily substituted and configured with environment variables.
Domain models and applications — base classes for domain model aggregates and applications. Suggests how to structure an event-sourced application.
Application-level encryption and compression — encrypts and decrypts events inside the application. This means data will be encrypted in transit across a network (“on the wire”) and at disk level including backups (“at rest”), which is a legal requirement in some jurisdictions when dealing with personally identifiable information (PII) for example the EU’s GDPR. Compression reduces the size of stored domain events and snapshots, usually by around 25% to 50% of the original size. Compression reduces the size of data in the database and decreases transit time across a network.
Snapshotting — reduces access-time for aggregates with many domain events.
Versioning - allows domain model changes to be introduced after an application has been deployed. Both domain events and aggregate classes can be versioned. The recorded state of an older version can be upcast to be compatible with a new version. Stored events and snapshots are upcast from older versions to new versions before the event or aggregate object is reconstructed.
Optimistic concurrency control — ensures a distributed or horizontally scaled application doesn’t become inconsistent due to concurrent method execution. Leverages optimistic concurrency controls in adapted database management systems.
Notifications and projections — reliable propagation of application events with pull-based notifications allows the application state to be projected accurately into replicas, indexes, view models, and other applications. Supports materialized views and CQRS.
Event-driven systems — reliable event processing. Event-driven systems can be defined independently of particular persistence infrastructure and mode of running.
Detailed documentation — documentation provides general overview, introduction of concepts, explanation of usage, and detailed descriptions of library classes. All code is annotated with type hints.
Worked examples — includes examples showing how to develop aggregates, applications and systems.
Register issues¶
This project is hosted on GitHub. Please register any issues, questions, and requests you may have.